
Using a version control system for software development is a standard procedure today. While things are pretty clear for ‘standard’ Eclipse projects, it is not that easy for Processor Expert projects. I’m using Processor Expert projects with Git and SVN (Subversion). I want to share here tips how to use Processor Expert projects with a version control system. Screenshots and vocabulary are for TortoiseGit and Git, but applicable to any other VCS (Version Control System).

Git Repositories View in Eclipse
To Version Control or Ignore, that’s the Question
In this earlier post I provided a dissection of the different files in a CodeWarrior Eclipse and Processor Expert project. There are two important types of files to know about in the context of a version control system:
- Derived Files: these are files generated or produced/derived from the sources. I do not want to have these in a version control system, as I’m able to create them with my source files. So I need to ‘ignore’ them for the version control.
- Non-Derived Files: these are all the files I need to build my project, mainly source and header files, but as well linker files and any other files which are not derived. I definitely want them to put under version control.
I’m using here a version control system for the development of a software project, and not to put the result of the project (e.g. the final application binary) under version control. As such, I only store into the repository what is needed to build my output file(s), but not the output file and the derived files (generated object files, etc). I’m able to regenerate the derived files, so storing both the source files AND the object files in the system creates redundancies. And storing duplicated information will be a source of mistakes.
💡 It can make sense to store *everything* into a version control system at the end of the project (e.g. including the compiler and libraries used), but this would be a different use case which is not covered here. I worked in projects where during the development only the source files were stored in the version control system, but at the release time (customer release) *everything* was stored in a different version control system, including the hard disk image of the PC machine producing the final build. And the build PC machine has been put into a safe place too. The requirement was to be able to build the same thing up to 10 years later again. As in that time frame the host operating system/compiler likely will change or even not be available any more, the decision was made to ‘version control’ everything. Hard core stuff 🙂
For a project under version control, it means to put the ‘non-derived’ (aka source) files under version control, and everything else has to be ‘ignored’. The important thing is that it should be possible for another developer to ‘check out’ the project from the system, and with that he is able to use and build that project.
💡 A good test is to ask another engineer to ‘pull’ your project from the repository and to build it: if this is possible,then everything is fine. If not, then maybe path settings are local to my machine (bad, bad, bad!), or I missed to commit files. It is like with backups: until you really restored the backup image, you cannot be sure that things are working 😉
The following shows a CodeWarrior Processor Expert (Kinetis) project using TortoiseGit: the files and folders with the green check mark are under version control, while the other files are not, because they are generated or derived:
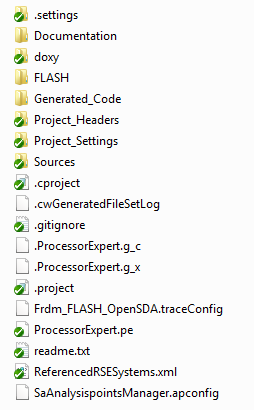
Project under Version Control
💡 For Git I have the ignored files listed in a file named .gitignore. For SVS this would be .cvsignore. Other version control systems use similar ways.
Processor Expert and Version Control
So I need to know what to ignore and what to put under version control.
File/Directories to ignore (NOT to put into a version control system):
- Documentation: this folder is generated by Processor Expert.
- FLASH: that folder name might be different for each project. It has the make files generated by the Eclipse build system and all the generated object and application binary files.
- Generated_Code: in this folder Processor Expert places all the generated source files
- .cwGeneratedFileSetLog: this file is generated by the CodeWarrior project wizard and has no usage to my knowledge. Typically I delete that file right away as not used.
- .ProcessorExpert.g_c and .ProcessorExpert.g_x are used by Processor Expert to keep track of the code generation what has been generated into Generated_Code. Therefore I do not need them in the version control system.
- SaAnalysispointsManager.apconfig: This file is used by SA (Software Analysis), and can be ignored too.
Processor Expert generated Memory and Linker File
Processor Expert can generate files for the debugger and linker: the memory map file for the debugger and the linker file for the linker. This is configured in the ‘Build options’ tab of the CPU component:

Processor Expert generated memory and linker file
Following the rules above, I would place them under version control, if they are not generated. Otherwise they are under version control.
Note: Even if the memory and linker files are generated, it can make sense to have it in the version control system: the files are text files (so easy to diff), and they rarely change.
Multi-User Development with Processor Expert
One of the biggest advantages of using a version control system is to collaborate with other developers. A version control system can diff and merge changes from multiple developers (or branches). But this only works well with text files. If you want to simultaneously edit binary files, then typically this is not supported.
💡 In Subversion (SVN) I can lock a file, do my change and then commit the binary file with an unlock. This will avoid that another developer is doing a change in parallel. Unfortunately, such a locking is not possible in Git (or I have not found out how to do this).
Processor Expert (at least up to MCU10.3) stores all its component settings in a single XML file: The ProcessorExpert.pe file is a XML text file:
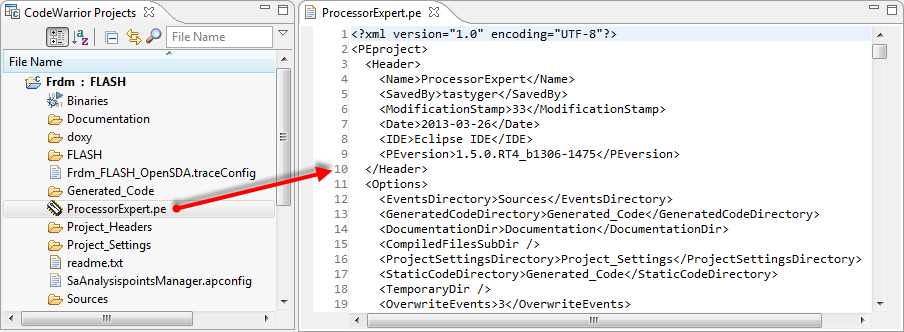
ProcessorExpert.pe XML file
While that XML file is a text file (so can be handled by a version control system), it is not a file you are supposed to edit by hand (unless you are an XML expert :-)). The problem is that if two users are doing changes in parallel on this file, a merge is typically *not* very hard to do.
❗ Merging technically would be possible. But because Processor Expert is creating conflicts (changing same lines for each user), this will result in merge conflicts. And these merge conflicts will corrupt the XML if you are not really, really careful.
Conflicts and the ProcessorExpert.pe
Just assuming that two developers are working in parallel on the same Processor Expert project, and they do in parallel Processor Expert changes:
- Both Jim and Joe have checked out the same version.
- Jim adds a BitIO component and commits the change.
- Joe adds a LED component and wants to commit it.
- Joe’s commit fails as there are conflicts:

Conflict on ProcessorExpert.pe
It creates a conflict, because Processor Expert was changing the same line in both branches:

ProcessorExpert.pe Conflict
So Processor Expert is storing a counter into the .pe file (ahhrg!). Of course this will be different for every code generation, causing unnecessary conflicts. But not only this, Processor Expert stores other information like user name and date information into the XML file, creating a constant source of version control system conflicts:

Header information in ProcessorExpert.pe
The above change would be easily to merge. But the difference in BitIO and LED component is much harder: There is a conflict between BitIO and LED:
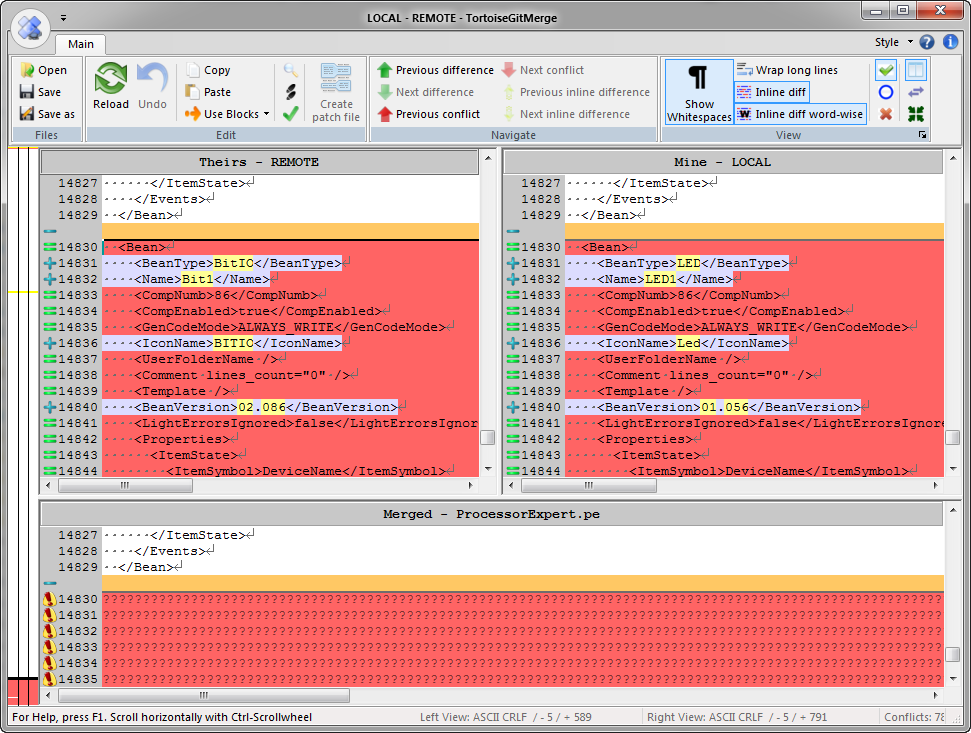
Component Conflict in ProcessorExpert.pe
Now this one will be really hard to merge :-(.
❗ Even worse: if your version control system tries to merge the two files, the resulting XML file will be corrupt, causing strange errors in Processor Expert.
So why to worry about the conflict? Especially new users with version control systems tend to simply ignore the conflict or even mark it as ‘resolved’. The thing is: this will badly bite you. For my above case, I will get the following conflict state in my directory:

ProcessorExpert.pe with Conflict
The version control system has marked the file with the exclamtion mark and asking me to resolve the conflict. I cannot simply ignore it, because that XML file has been changed:

Merge Information in ProcessorExpert.pe File
Without manual merge, that file will not be usable with Processor Expert:
Failed loading file ProcessorExpert.pe Resource is out of sync with the file system: '/Frdm/ProcessorExpert.pe'. Failed loading file ProcessorExpert.pe Error on line 31: The content of elements must consist of well-formed character data or markup.

Failed loading file ProcessorExpert.pe
At this time is it now probably best to perform a ‘revert’ operation with the Version control system and to restore the previous version of that file :-(.
Git Revert Operation
Dilemma with the ProcessorExpert.pe
Because Processor Expert stores everything in this single XML file, and because every change in the Processor Expert settings will cause a change which is very likely causing a conflict, that XML file pretty much has to be handled like a binary file. That means I need to ‘lock’ and ‘unlock’ if I want to do changes. And that I must serialized changes to that file.
💡 If Processor Expert would use different XML files for each component or ‘component setting domain’, that would greatly reduce the likelihood of conflicts. E.g. if there would be XML files for each component including the CPU component, and as long as multiple users are not changing the same component, things would work out much better.
In order to avoid this conflict, there are several options:
- Only one owner: Only one person is supposed to do changes to the ProcessorExpert.pe file. That works pretty good in small teams.
- Clear to Change: if someone needs to do a change, it announces the request to change to the rest of the team. This will allow others to commit their pending changes (if and). Once the request is granted, the change is committed and everyone pulls the change from the system.
💡 I can set the ProcessorExpert.pe file to read-only from the Windows Explorer. This will prevent Processor Expert to write it.
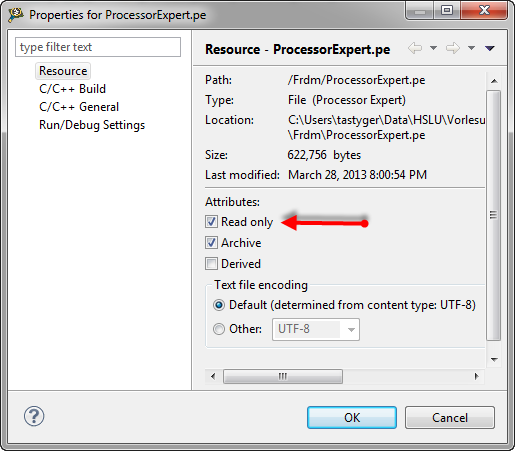
Read Only File
Setting the ProcessorExpert.pe file to read-only will prevent that it gets modified by Eclipse/CodeWarrior. I still can ‘save’ the modification, and there will be no error dialog. Instead, the failure will be written as message to the Processor Expert Console View:
Failed saving project file ProcessorExpert.pe File /Frdm/ProcessorExpert.pe is read-only.
Saved Processor Expert File
If I change settings in Processor Expert component, this is marked with an asterisk (*) like for any other Eclipse views:

Changed Component Settings
💡 Use CTRL-S (for save) to save the component settings
What I have seen is that there can be problems if the settings have not been saved, and I do an update/pull with the version control system for the underlying ProcessorExpert.pe file.
❗ Processor Expert seems not be aware that the underlying XML file has been changed, or at least not every time. So if I get an updated ProcessorExpert.pe file through the version control system, the settings shown in Eclipse do not reflect this. Even worse: if I have unsafed changes in Eclipse and then save my settings, the new version from the version control system gets overwritten. If I will commit that new file, the wrong file gets commited to the repository.
So it is possible that Eclipse/Processor Expert is not showing the content of the file on the disk, but rather the ‘cached’ version in RAM. As a consequence, I always save my settings before doing a version control operation to ensure data integrity (e.g. with the Save All button).

Save All Button
Recommended Process
I recommend the following process to work with Processor Expert under version control in a team development environment, where multiple users might change the Processor Expert component settings:
- The developer who wants to make the change gets a ‘lock’ to the ProcessorExpert.pe file. Either through a lock in the version control system (if supported, e.g. in SVN), or by talking with the other developers.
- He performs the change and closes the project to ensure the XML file is written to the disk.
- He commits the change and re-opens the project in his workspace.
In order to avoid wrong update of the ProcessorExpert.pe, following needs to be done for a version control system ‘pull’:
- Close the Processor Expert projects (menu Project > Close Project) to ensoure the settings are saved.
- Do the ‘pull’. This will update the local files.
- Re-open the Processor Expert project (menu Project > Open Project) to make sure the Processor Expert information gets loaded.
💡 In case of a conflict, I recommend to perform a revert operation and then do a serialized change. Painful, but in my view the only way to resolve conflicts.
Summary
Using Processor Expert with a version control system is not very easy. The fact that Processor Expert stores all its important settings in a big XML file makes it hard to collaborate in a team of developers. The only suitable way to deal with the ProcessorExpert.pe file is pretty much to handle it like a binary file. That needs precaution and awareness that any conflicting changes easily can result in a mess. It is better to coordinate changes of the ProcessorExpert.pe file in a team, so the changes are serialized. And to make sure that settings/project are always stored to disk before doing version control operations, and reloaded afterwards. So the key is to serialize Processor Expert changes.
Using a version control system in a single developer environment is not a problem, and already adds a lot of value. Knowing about the mechanics behind it, and what implications Processor Expert projects have, will avoid a lot of frustrations (and corrupted projects). But how Processor Expert stores currently (at least up to CodeWarrior MCU10.3) its information, it is not designed to work with a version control system out of the box. But I hope that with above tips the traps and pitfalls can be avoided, and that with future Processor Expert releaes and changes things get ‘version control system friendly’.
Happy Versioning 🙂

Erich, thanks very much this was a very informative post! I’m a “team of one” right now so this doesn’t pose a problem for me, but I really hope the Code Warrior development thinks harder about VCS support for the next release, as I could see this turning a lot of users off in a big way. The only other comment I had was that Eclipse has plug-ins for tighter VCS integration (at least with SVN). Do you know what version of Eclipse (i.e. Ganymede, Galileo, Helios, Indigo, etc.) Codewarrior 10.3 is built upon? Knowing that, it’s just a matter of pointing Eclipse at the right update site to get the Team Collaboration plugin (I think it’s called Subversive). That way you can do all your VCS operations right there in Eclipse.
LikeLike
Hi Victor,
yes, I’m using VCS plugins integrated into Eclipse as well. I tried SubVersive a while back, but it did no work well for me. What worked very well is Subclipse. For Git I’m using eGit. The Eclipse plugins are great, but still I want to use a non-Eclipse client like TortoiseSVN and TortoiseGit. Because not everything can be done with the Eclipse client, and I want to have some other ways to deal with my versioned files. As for your other question: CodeWarrior MCU10.3 is using Eclipse 3.7 which is the Indigo release.
LikeLike
I agree with your opinion Erich. Now, I’m using Subversive plug-in in my Processor Expert projects, but also I have other SVN client as TortoiseSVN with more options available. Furthermore, in my RTOS (MQX4.0) projects with Subversive I do the same procedure with “Derived Files” directly over MQX folder installation. For example, I share the BSP library with all necessary beans uploading BSP library to remote repository…
One post very useful!
LikeLike
Pingback: First Steps with the P&E Tracelink | MCU on Eclipse
Hello Erich,
thanks for this tutorial, it’s very useful.
I have an existing codewarriror (with Processor Expert) project and I need to put it into SVN repository.
I follow your post and I delete the Generated_Code folder and other files.
Before commit to SVN, I try to compile the project and I get some error related to the files into Generated_Code folder.
What I do with Generated_Code Folder?
If I maintain it into project and I remove other files I can compile the project.
Any suggestions?
Thanks
Federico
LikeLike
Hi Federico,
what kind of errors do you get? In general, no generated files are stored in the version control system, as they are generated.
So my suggestion is that you need to fix the errors first, before committing the project.
LikeLike
Hi Erich,
When I compile the project I haven’t errors, but if I remove Generated Code folder and I recompile I get some errors. For example missing PE_Types.h and other files contained into Generated Code folder.
What can I do?
Thanks
Federico
LikeLike
You need to generate code with Processor Expert. Right Click on the .pe file and choose ‘Generate Processor Expert code’.
LikeLike
I enjoyed reading your article. I would like to know how to setup Code Warrior and Processor Expert so that it does not contain fixed paths (i.e., c:\workspace\projectName\) so that others can down load and put the project in the location that they wish? Also, I am not sure how to import the code into Code Warrior, on other SDK’s I just went to the location that I down loaded the code to and open the project and was up and running but Code warrior does not seem to like that way of doing things.
LikeLike
Hello Eric,
We are using Microsoft Visual Studio Source Control (now my question may go for all version control systems).
How do I import code (which has Processor Expert code) into Code Warrior? (On other SDKs I just pointed the project open to the location path and clicked on the project file and everything was okay but does not seem to work with Code Warrior.)
Also how do I set up code warrior to not use fixed path names?
LikeLike
Hi John,
I have not used the Microsoft version version control system, but I think this is probably not relevant. There are several ways importing projects in Eclipse (and CodeWarrior), see https://mcuoneclipse.com/2012/05/07/exporting-and-importing-projects-in-eclipse/. The most common one is to use File > Import > Existing Project. In CodeWarrior you can as well drag&drop the project folder or the .project file into the project view. Or with the version control plugin (not sure if this exists for Microsoft Visual Studio Source Control) with directly importing from the repository.
I’m not sure what you mean about fixed path names: if you setup correctly your project (using project relative paths), then the .project and .cproject files are using those, and not absolute paths. And the .project and .cproject are the files needed and describing your project. I have not faced any issues with path things that way, even with moving between host machines (e.g. Windows and Linux). Just make sure you are using *Unix* path separators for relative paths (slash and not back-slash) to keep things portable between hosts and machines.
I hope this helps,
Erich
LikeLike
Thanks Erich, I will look over the information that you have sent. From first look, I believe this will be of great help. What other tutorials do you have, I would like to learn more about using Process Expert, I am so used to programming the GPIO lines directly that this is kind of foreign to me.
Thanks for the information and the great tutorials that you have put out.
LikeLike
Hello Eric,
Great article, I just love your posts on Eclipse, very educative.
I’d like to ask you if you know of any way of getting the version number or number of commits automatically generated from Eclipse to use in the source code? Like automatic version numbering of the firmware… What’s your approach on this?
Thank you for your attention.
Keep up the good work 😉
LikeLike
I’m using __DATE__ and __TIME__ standard macros in the C code which then are used to identify the firmware version. In general I do not recommend to use version number from a VCS (e.g. Git), as for example the Git hash key does not make much sense to include. Better maintain a version.h with a version number in it which is updated as part of the release process. Other than that, there is a discussion on this topic here: http://stackoverflow.com/questions/10564510/how-to-embed-version-information-in-source-code-with-mercurial. The general option is to trigger a shell script as part of the build process to retrieve to generate the version information.
I hope this helps,
Erich
LikeLike
A problem we are having here is that in KDS, the original “Beans” and “Drivers” directories for the internal PEx repositories are installed deep inside the Application folder, and are not simple to put under version control – at least without putting the entire application under VCS… Is there a simple way to divorce the Freescale-supplied PEx components from the Application?
LikeLike
I have not done this, but I think it should be possible. Have a look at Window > Preferences > Processor Expert > Repositories and Paths. This lists all the locations used. So you could move e.g. the ‘Kinetis’ repository content your own location for Git, disable that default repository and add one pointing to your git location.
LikeLike
Hi Erich,
I´m just trying my first steps using VCS and I want (need) to add a new CVS repository on KDS but I coudn´t do it so far. Is there a good reference manual or can you explain me how to create a local host at my side? I tryied to use my user´s pc name, my IP adress, etc. and didn´t work…
LikeLike
Hi Marcio,
my recommendation is not to use CVS: it is simply not a modern version control system any more. I only have legacy things in CVS and moved everything to git instead. As for tutorials, simply search the web for ‘git tutorial’ and you will fine a lot of them.
LikeLike
Ok Erich,
I´ll look for GIT, thanks.
LikeLike
When creating a project (in CW 10.7) with PE, there is a choice for “Linked” or “Standalone”.
See description of this on page 126:
Click to access PEXDRVSPEXUG.pdf
What are your thoughts on committing the static files to version control vs not.
LikeLike
Hi Paul,
I always use ‘standalone’ projects, using linked projects have the problem that they might not build any more if the links are not maintained.
And I do put the static_files into the version control system, as they (for unknown reasons?) are only created once at project creation time.
if you do not put them into the version control system, your project will not build from it.
Erich
LikeLike
Hi Erich,
as ways spectacular article.
I’m using MCUXpresso 10.1.0 and have a standard project created by SDK Wizard. I’d like to use SVN for version control, but its not clear what files/directories I should control.
Thank you for your suport.
Gustavo Costa
Electrical Engineer
LikeLike
Hi Gustavo,
I see if I can write a short article on this subject over the next week-end.
LikeLike
Hi Gustavo,
you might have a look at the examples I have for the SDK on GitHub, for example. https://github.com/ErichStyger/mcuoneclipse/tree/master/Examples/MCUXpresso/FRDM-K64F/FRDM-K64F_uCUnit
All what you need is that .gitignore, and you have to exclude the output folder (e.g. Debug). I usually ignore as well the .settings folder as in my environment that one is not needed (or better: recreated by Eclipse).
LikeLike
Pingback: Tutorial: Git with Eclipse | MCU on Eclipse
Hi Erich,
I need to generate a 6 square pulses from FRDM-K22F development board, each pulse is 3.1us.
I tried to use BitIO to pulse the signal but I have ripples in the top and bottom of the signal. Any better suggestion of how to create a more clean signal, please?
Regards
Banu
LikeLiked by 1 person
If you have any ripples, it means you have problems with noise to the signal. Check what kind of interferences you get (50/60 Hz?). Or you need to have a dedicated op-amp circuit to generate the clean signal you need.
LikeLike
It will be this one of the reasons why NXP decided not give support the expert processor?
LikeLike
No, I don’t think so. To get Processor Expert XML files easier to work with version control systems would just required to split the component settings into multiple XML files and removing the timestamp/machine information (or move it to a different file).
LikeLiked by 1 person
Pingback: Organizing Projects with Eclipse and Git | MCU on Eclipse