
If you ask your colleagues about ARM Cortex® M33 core, they’ll most likely remember that the ARMv8-M architecture adds the (optional!) TrustZone® security extension. But one, overlooked but significant new feature in ARMv8-M is the new coprocessor interface.

With the LPC55S69 microcontroller, NXP decided to add an extremely powerful DSP Accelerator onto this coprocessor interface, named PowerQuad. In this week’s video series I’m investigating the PowerQuad, and the functions that it provides.
PowerQuad is a collection of mathematics ‘engines’ that accelerate common functions. It works natively in the floating point datatype, but can convert and scale integer datatypes ‘on-the-fly’. Of course, the Cortex® M4 introduced the ‘DSP extensions’ to the instruction-set, but these are more single-instruction, multiple data (SIMD) opcodes and not really ‘DSP instructions’. For example, M4 can perform a MAC (multiply and accumulate) instruction on 2 sets of 16-bit operands in one cycle. PowerQuad is very different – it performs complete FFTs or inverse-DCT, as well as atomic functions such as ln(x) or e^(-x) where there is not a corresponding Cortex® M4 or M33 instruction.

In the top right corner of the diagram above you can see 4 bus interfaces. Of course, to accelerate mathematical functions the PowerQuad may need fast access to memory resources. And so the PowerQuad has a DMA-interface to private RAM. This has a 128-bit interface and is used for storing operands, intermediate results and output data. For simple unary or binary functions (sin(x), biquad(x), float(x1/x2) etc) the opcodes and operand(s) are passed over the coprocessor interface. This new interface is 64-bits wide and new instructions in the ARMv8-M architecture can move one or two core registers into the coprocessor in one clock cycle. This enhances the speed of the PowerQuad. And owing to the architecture of the PowerQuad, two of these coprocessor functions can operate at once, resulting in fantastic vector maths. PowerQuad will calculate both sin(x) and cos(x) in parallel – in either integer or floating datatype – in 9 clock cycles. The focus of my video this week is exclusively on the coprocessor-accelerated functions.
Some DSP algorithms require more data than just two floating-point operands. And so PowerQuad has an AHB interface to the LPC55S69 crossbar, making it a memory-mapped peripheral. And since PowerQuad requires fast memory access, it is also a AHB master that behaves much like a DMA controller. I’ll investigate these interfaces next week.
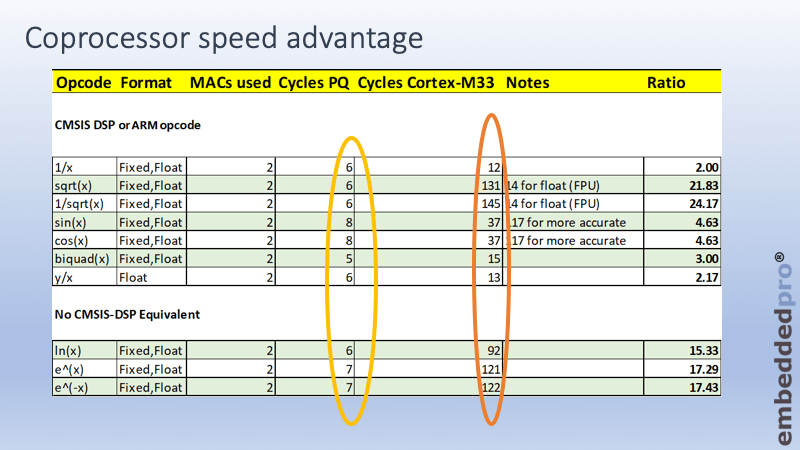
The performance advantage of using PowerQuad over CMSIS-DSP code is obvious. For a simple float divide the PowerQuad requires 6 clock cycles. Cortex M4F and Cortex M33 have a float divide instruction, and this requires 13 clock cycles. So PowerQuad is twice as fast. When we consider acceleration of functions that the core (or CMSIS -DSP library) does not provide such as the natural logarithm ln(x) then the PowerQuad performs this in 6 clock cycles. The same calculation running on the core would require 92 clock cycles, making a x15 increase in speed.
There is much more information in the video of this blog, which you’ll find here:
I trust that you find it informative… please feel free to leave comments or ask questions. And come back next week when I look at the ‘other side’ of PowerQuad and the remaining ‘engines’ such as FFT engine and Matrix engine.
If you enjoy this video, there are plenty more on my embeddedpro® YouTube channel covering topics such as Getting Started with LPC55S69-EVK, using MCUXpresso IDE Config tools and much more.
