
Welcome to ‘Alice in Wonderland‘! For a university research project using an ARM Cortex-M33 we are evaluating position-independent code as way to load applications or part of it with a bootloader. It sounds simple: just add -fPIC to the compiler settings and you are done.
Unfortunately, it is not that simple. That option opened up a ‘rabbit hole’ with lots of wonderful, powerful and strange things. Something you might not have been aware of what could be possible with the tools you have at hand today. Leading to the central question: how is position-independent code going to work with an embedded application on an ARM Cortex-M?
Let’s find out! Let’s start a journey through the wonderland…
Outline
Position-Independent code (or PIC) is what is suitable for shared library code or if you want to use a loader to load and execute code anywhere in your address space. Basically it means that the code can run ‘anywhere’.
Some use cases:
- Copy code from slower FLASH to faster SRAM for execution.
- Build a library which can be loaded by different applications at runtime.
- Execute a loadable task anywhere in the memory
- Build application image position independent to minimize future update size
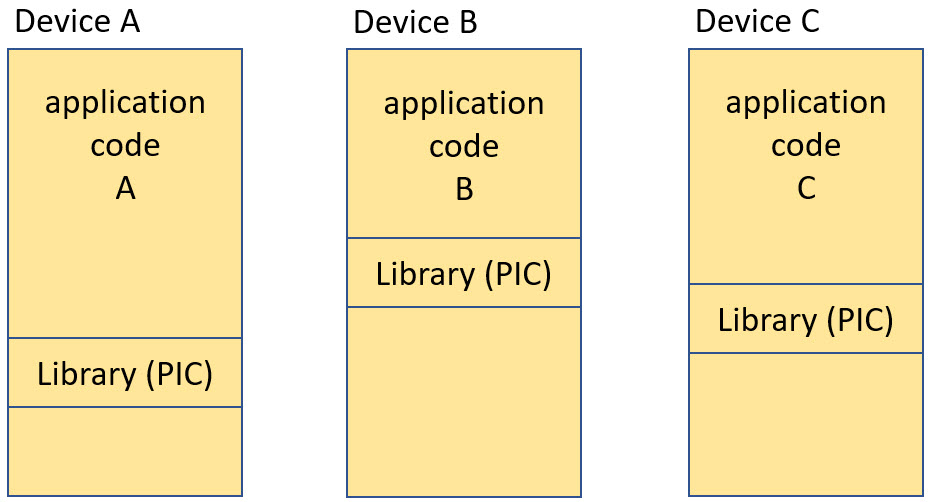
- Provide the a library to many devices in the field, and each device can load or have that library in different memory ranges, e.g. to have flexible memory arrangements
- Support a loading mechanism to load code e.g. from a memory device/SD card and then run anywhere in the memory
In essence: a library shall be using position-independent-code (PIC) so it can be placed and run at different addresses on a device. With using PIC the data amount for firmware updates over low bandwidth network connections like LoRa could be minimized too.
There can be certainly an unlimited number of use cases. So I’m not going to address any of them in this article directly. Instead I want you to give the insights so you can pick and choose your own implementation.
For most applications running on ARM Cortex-M, PIC is not needed or even might be the wrong solution, because usually there is no dynamic loading of code involved. But with the growing usage of bootloaders and loadable ‘applets’ especially in the ‘IoT’ world, PIC could be an interesting solution.
While PIC is standard for Linux and host development, it is far less known to the embedded world. On one hand because standard vendor tooling does not cover it with examples, on the other hand it is rather complex and requires knowledge and a loader of some kind. Nevertheless I think understanding how PIC works on an ARM Cortex-M is interesting and provides insights into the workings of compiler and linker, which can be useful even if you don’t consider using PIC.
In this article I’m using the MCUXpresso IDE with the LPC55S16-EVK. But you should be able to apply the principles to any other IDE or board.

💡 I’m using the LPC55S16 which is an ARM Cortex-M33. However the GNU ARM Embedded compiler in version 9.31 has an issue preventing properly PIC code for M33 (warning: thumb-1 mode PLT generation not currently supported). As a workaround code can be generated for the M4 instead.
GCC -fPIC Option
The GNU compiler (GCC) has a dedicated option to generate position independent code:
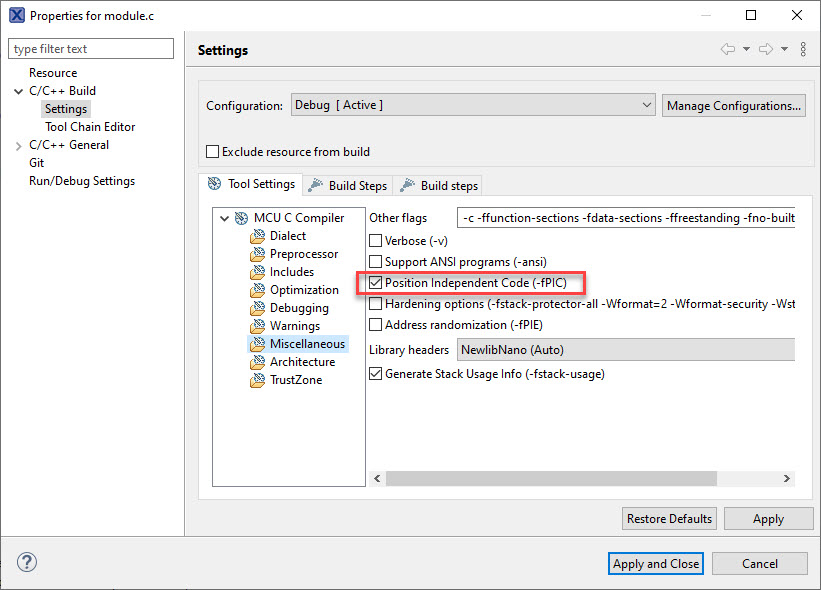
So what is the effect of this option? For this we need to have a look at some code examples.
Building a Shared Library
The example on GitHub includes a ‘subproject’ to build a shared library (.so) or ‘shared object’.
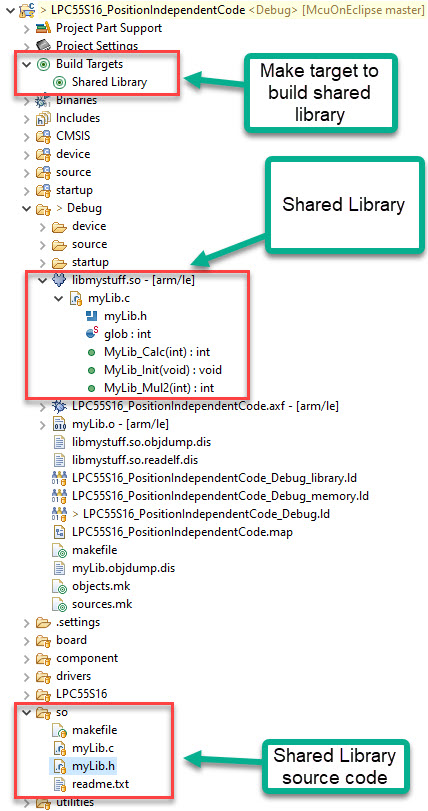
The make file builds the shared library (libmystuff.so) which then can be used in the application.
Notice the nice ‘shared’ icon in Eclipse for the library:
The reason is because the ELF type is ‘DYN (shared object file)’, confirmed by
arm-none-eabi-readelf -l "libmystuff.so" > "libmystuff.so.readelf.dis"
Elf file type is DYN (Shared object file)
Entry point 0x174
There are 3 program headers, starting at offset 52
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
LOAD 0x000000 0x00000000 0x00000000 0x00190 0x00190 R E 0x10000
LOAD 0x000190 0x00010190 0x00010190 0x00088 0x0008c RW 0x10000
DYNAMIC 0x000190 0x00010190 0x00010190 0x00078 0x00078 RW 0x4
Section to Segment mapping:
Segment Sections...
00 .hash .dynsym .dynstr .rel.dyn .text
01 .dynamic .got .bss
02 .dynamic
Variable Data Access
PIC sounds it is all about code, but it is about variables too. The idea of having a library loaded anywhere in the memory means that the data needs to be position independent too.
For this, let’s have a look at two functions accessing a global variable:
int var;
void foo(void) {
var = 1;
}
void bar(void) {
var = 2;
}
Let’s check the disassembly of this code, without using PIC, just as you would use it in a normal way:
00000000 <foo>:
0: 4b01 ldr r3, [pc, #4] ; (8 <foo+0x8>)
2: 2201 movs r2, #1
4: 601a str r2, [r3, #0]
6: 4770 bx lr
8: 00000000 .word 0x00000000
8: R_ARM_ABS32 .bss.var
00000000 <bar>:
0: 4b01 ldr r3, [pc, #4] ; (8 <bar+0x8>)
2: 2202 movs r2, #2
4: 601a str r2, [r3, #0]
6: 4770 bx lr
8: 00000000 .word 0x00000000
8: R_ARM_ABS32 .bss.var
The compiler adds a 32bit absolute relocation (R_ARM_ABS32). This relocation is a constant in the code at the end of the function which gets resolved by the linker. The code loads that address PC-relative into the register r3:
ldr r3, [pc, #4]
and uses a register indirect addressing:
str r2, [r3, #0]
From a data access flow point of view it looks like this: Each function accessing the variable includes a PC-relative constant which holds the address of the variable. In the example I assume that the variable ‘var’ is located at address 0x2000’0000 in RAM.
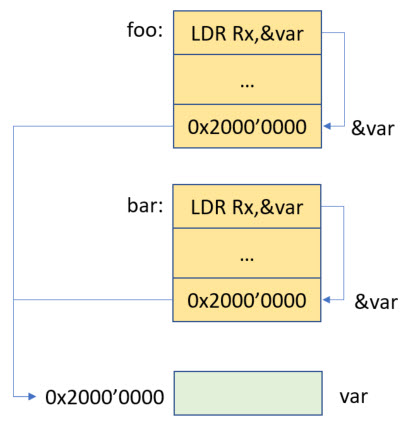
Green color is used for RAM (R/W) and orange for FLASH (RO). Note that in above picture the functions foo and bar are both position independent already: they could be placed anywhere in the address space.
💡 Keep in mind that we did not look into how foo and bar get called. This will be a discussion later on. Just let’s focus first on the variable access, trust me.
For a position-independent library the above is not ideal in several ways:
- The address of the variable is fixed by the linker at link time. If the variable needs to be at a different place in memory, then a loader at runtime needs to go through a list and patch every reference to that variable. This is doable, but will take time for the loading process. But access is very efficient in the code.
- For embedded targets the code is usually in FLASH memory. The constant(s) in the code are in FLASH memory too, requiring the loader to deal with this (load first in RAM, patch and then program FLASH or program the flash in multiple iterations which is not feasible).
- While the code could be moved, the data cannot until the loader would patch all references to the variables and their addresses.
Variables Access with -fPIC: GOT
Now let’s have a look at the same code compiled with -fPIC compiler option:
00000000 <foo>:
0: 4b03 ldr r3, [pc, #12] ; (10 <foo+0x10>)
2: 447b add r3, pc
4: 4a03 ldr r2, [pc, #12] ; (14 <foo+0x14>)
6: 589b ldr r3, [r3, r2]
8: 2201 movs r2, #1
a: 601a str r2, [r3, #0]
c: 4770 bx lr
e: bf00 nop
10: 0000000a .word 0x0000000a
10: R_ARM_GOTPC _GLOBAL_OFFSET_TABLE_
14: 00000000 .word 0x00000000
14: R_ARM_GOT32 var
00000000 <bar>:
0: 4b03 ldr r3, [pc, #12] ; (10 <bar+0x10>)
2: 447b add r3, pc
4: 4a03 ldr r2, [pc, #12] ; (14 <bar+0x14>)
6: 589b ldr r3, [r3, r2]
8: 2202 movs r2, #2
a: 601a str r2, [r3, #0]
c: 4770 bx lr
e: bf00 nop
10: 0000000a .word 0x0000000a
10: R_ARM_GOTPC _GLOBAL_OFFSET_TABLE_
14: 00000000 .word 0x00000000
14: R_ARM_GOT32 var
You will notice that there is now more code (additional indirection) and two relocations which are using the GOT (Global Offset Table):
- R_ARM_GOTPC: PC relative offset to the Global Offset Table
- R_ARM_GOT32: offset of variable inside the Global Offset Table
The important point here is that R_ARM_GOTPC is a relative offset between the current PC and a section where there is a GOT (Global Offset Table) which contains the effective addresses of the variables. The when placing code and data knows the relative offsets between the sections.
So what happens is the following:
It loads a the the address of the GOT which is an offset between the current PC position and the actual location of the section which contains the GOT in R3:
ldr r3, [pc, #12]
add r3, pc
Then it loads the offset of the variable inside the GOT table (entry inside GOT) into R2:
ldr r2, [pc, #12]
Finally, loads the address from the GOT entry:
ldr r3, [r3, r2]
Here, R3 points to the variable and can be used to store the value in R2:
movs r2, #2
str r2, [r3, #0]
The picture below shows the relationship of the entries:
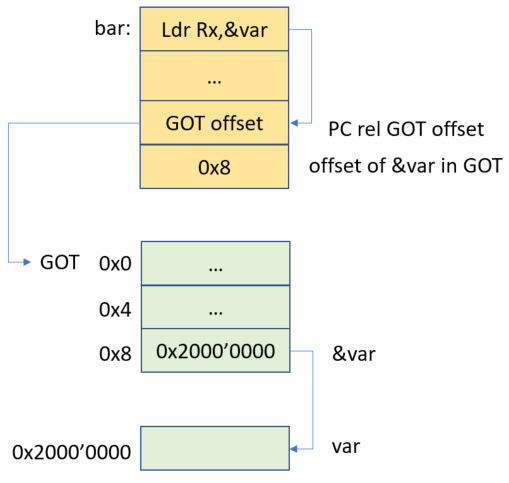
Note that above picture shows the GOT in RAM, but it could be in FLASH memory too.
So what we do have with this?
- The loader is faster, as it only needs to update the GOT and not all the different variable references in the code.
- The variables can be moved anywhere in RAM
- The variable access is slower, as one extra indirection
- The distance between the code section and the GOT section is fixed: if I move the code section, I do have to move/place the GOT section too: the code section and the section with the GOT needs to have the same distance.
So with this, I could have a code section followed by a GOT section and load both anywhere into RAM: I would have to update the variable addresses in the GOT table and accesses and code will be position-independent.
Setup the GOT Table
The question is: how to setup or fill the GOT table with the addresses of the variables? One way would be to provide the needed information to the loader (e.g. with a table or something similar). Another way would be for the loader to read the information from the library/object file: this is for example what the loader in Linux does, but that’s certainly out-of-scope for an embedded loader on a microcontroller.
Another way is to have the linker generate that information: that way I can link (well, load) a position independent library or object file into my application. I could use the linker information as data structure for an embedded loader too.
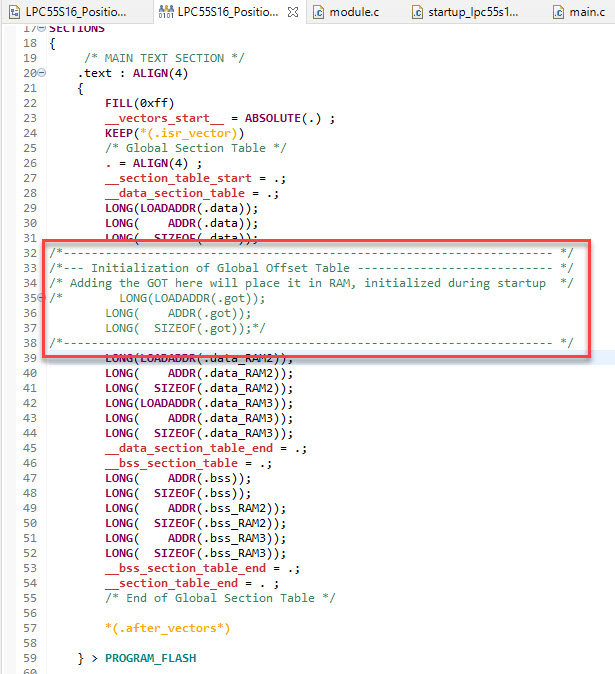
For this, I need to tell the Linker to create the needed initialization for the GOT. This requires the correct settings in the linker files. On MCUXpressso IDE, the easiest way is to disable the automatic managed linker script:
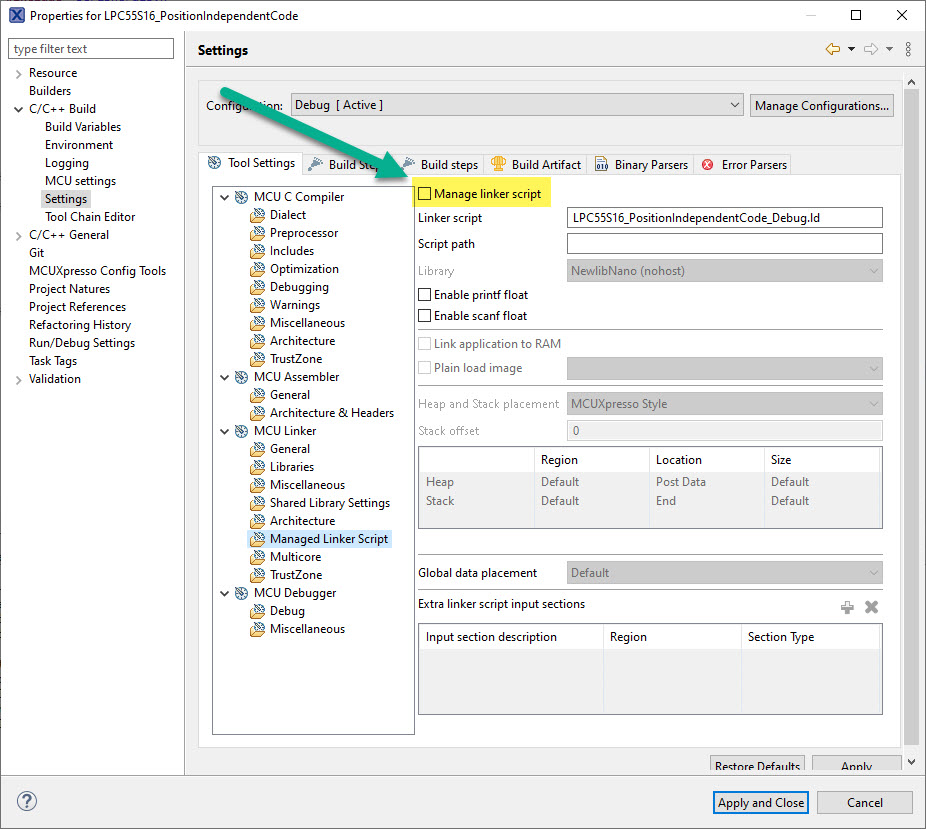
To make sure the GOT gets initialized during startup code, add the .got initialization to the linker file:
/*------------------------------------------------------------- */
/*--- Initialization of Global Offset Table ------------------- */
LONG(LOADADDR(.got));
LONG( ADDR(.got));
LONG( SIZEOF(.got));
/*------------------------------------------------------------- */
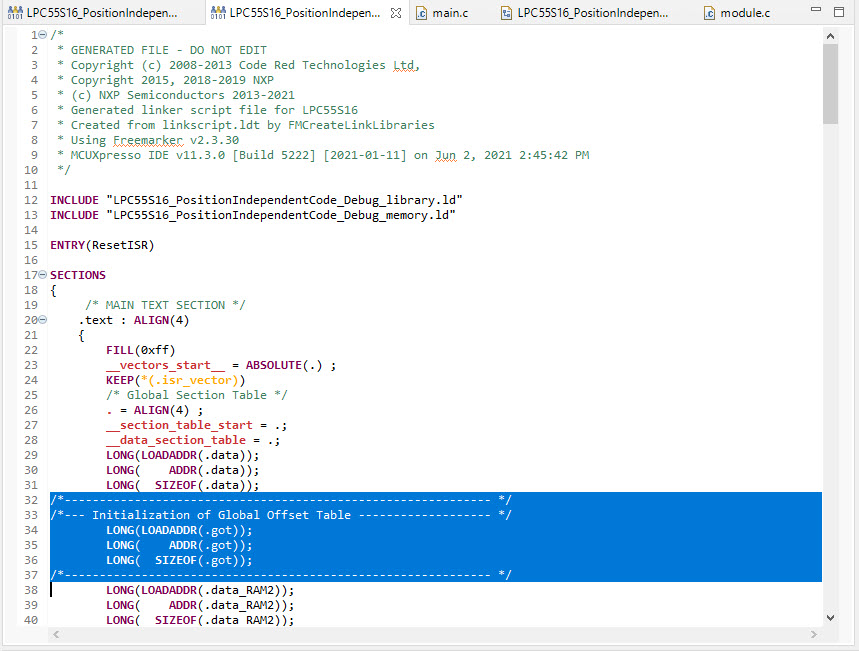
Check in the linker .map file that the initialization data gets added:
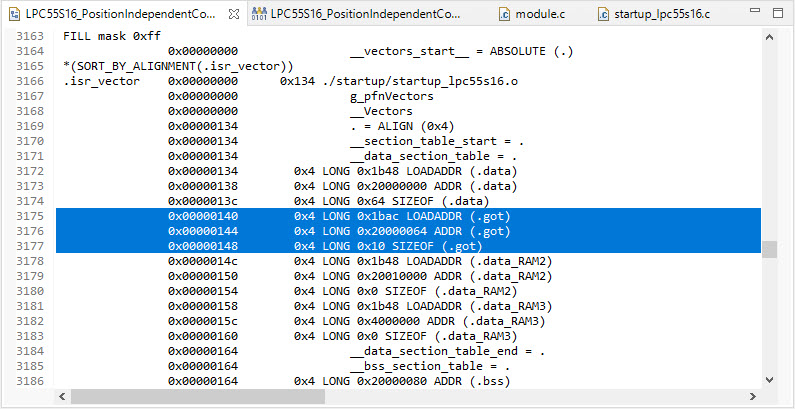
In the above case the GOT table (.got) is allocated at address 0x2000’0064 (SRAM) with a size of 0x10 and the initalization data gets copied from 0x1ba (FLASH).
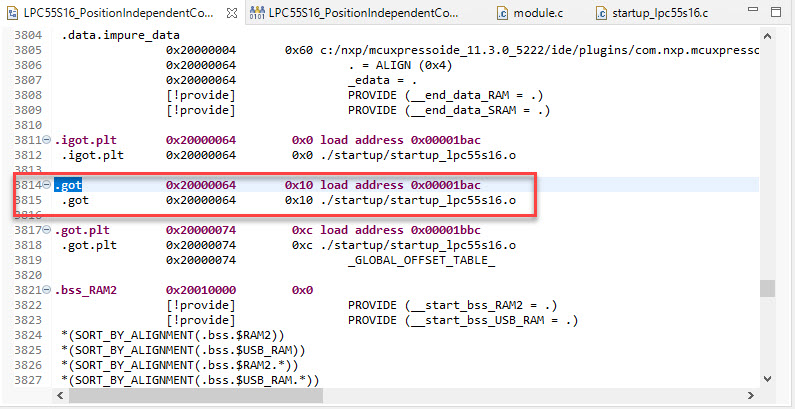
That way the GOT gets initialized during the ‘copy-down’ in the startup code:
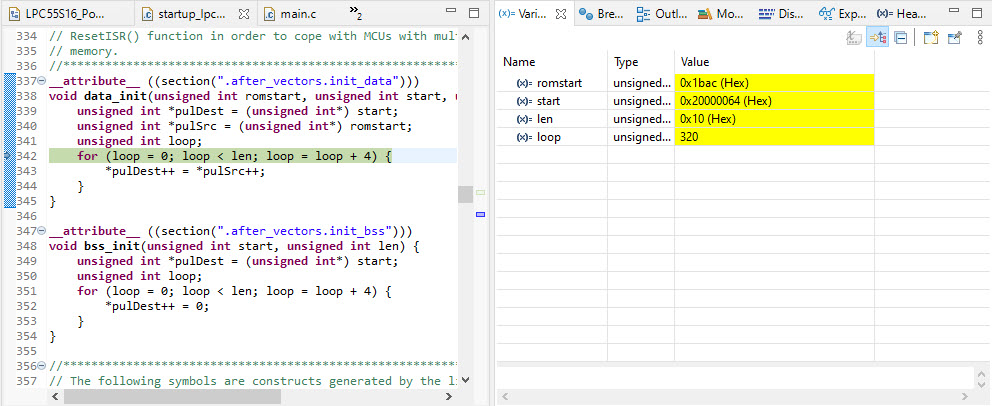
The above is using RAM for the GOT so you easily can change it during runtime. To have the GOT directly in FLASH memory:
Do not have it listed as above for the startup code initialization, e.g. comment it out:
Instead, just place it into Flash:
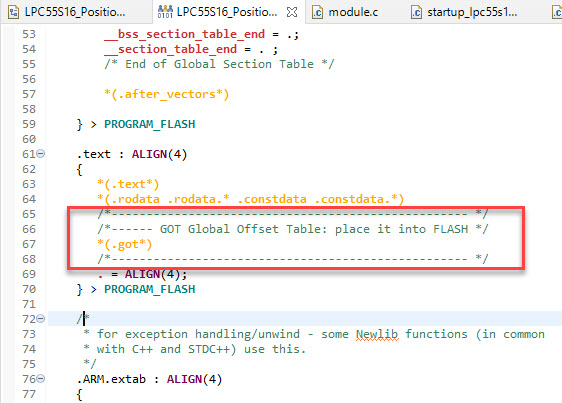
This places the GOT table into flash memory:
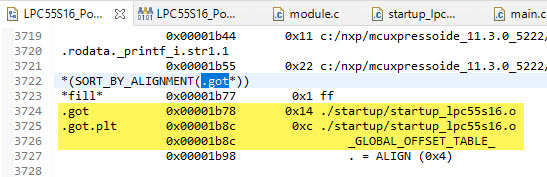
With this we have reached position-independent data processing :-).
Function Calls: PLT
So far we talked about variables. But what about function calls?
Let’s first check a simple case of a function call inside a library, this time without -fPIC: it calls a function inside the library and an external one:
void foo(void) {
var++;
}
extern void foobar(void);
void bar(void) {
foo();
foobar();
}
Checking the assembly code gives this:
00000000 <bar>:
0: b508 push {r3, lr}
2: f7ff fffe bl 0 <bar>
2: R_ARM_THM_CALL foo
6: f7ff fffe bl 0 <foobar>
6: R_ARM_THM_CALL foobar
a: bd08 pop {r3, pc}
So this all looks good as it uses relative branch-and-link (bl) instructions. So if the library does calls inside, all is fine. But what about if I want to call the library functions from outside?
For these it needs something similar but more complex: the PLT or Procedure Linkage Table.
One could think that the previous approach of using the GOT could be used for function calls too: there would be just an additional indirection for the function call. Actually this is what would happen if using function pointers for calling the library functions: function pointers are just data pointing to a code to be executed.
But actually the whole position-independent code is driven by a larger concept: dynamic loading or shared libraries. This concept is used on Windows with DLL (Dynamic Link LIbraries) or Shared Objects (.so) on Linux: the ability to share code between processes and between applications. It means that a code can be re-used and shared: and for this it needs to be position-independent too. And this is handled by a ‘loader’ which loads the executable and as well any referenced (shared) libraries.
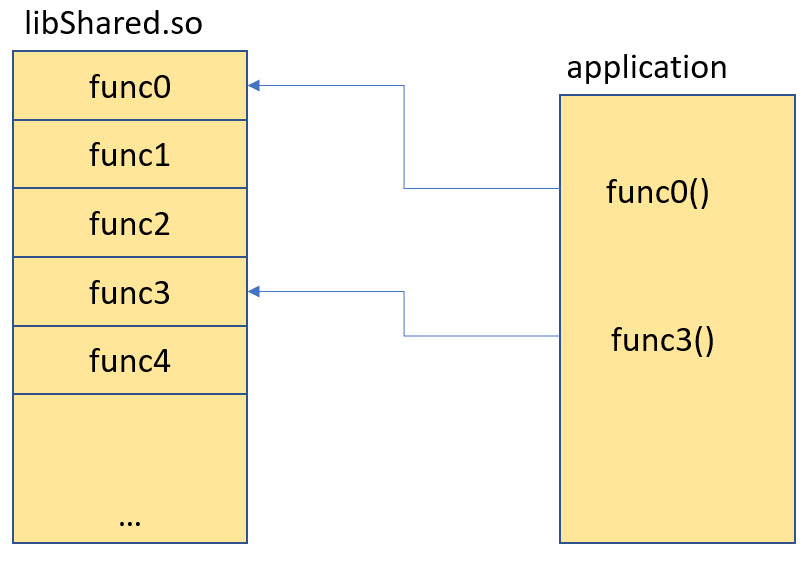
I’m not going too much into the details how these loaders work, because in this article I don’t want (or need) a runtime loader: instead I want to have position-independent code which can be ‘loaded’ by the debugger or the bootloader: to they are the very simplistic loaders in my case.
So what the loader has to do is to ‘bind’ the call from the executable to library. This is done with an extra indirection: That binding allows to have the shared library placed anywhere in the memory and position independent.
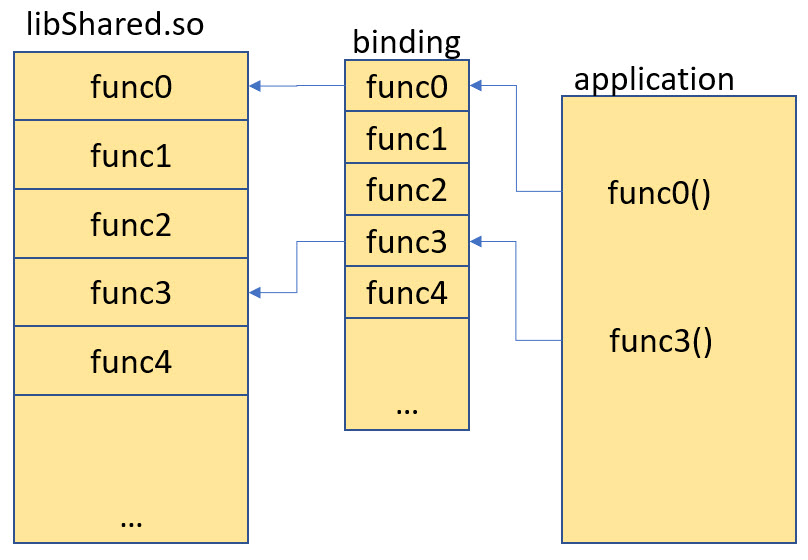
On a loader like the one on Linux or Windows which loads the executable, one main goal is loading speed: In many cases a library can have many, many functions, but probably the executable using the library only needs a few. That’s why on loading of the application and library, the bindings are not resolved immediately. They are ‘delayed’ and done only done ‘on demand’ for each first call of the library function.
For this there in addition to the GOT an extra PLT (Procedure Linkage Table) which acts as a ‘trampoline’:
The image below shows the sequence when the library function ‘func’ gets called the first time:
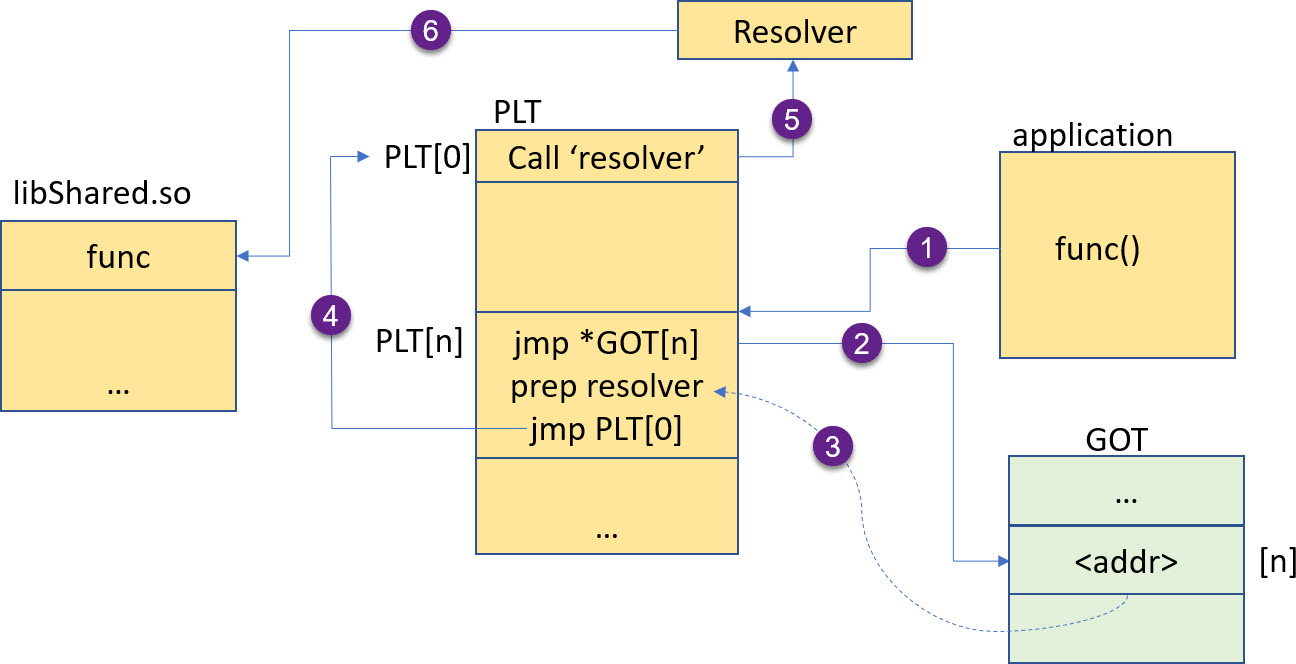
- The library function gets called in the application code. The call does not go directly to the library, but to a PLT entry instead. The PLT entry is is small piece of code and acts as trampoline
- The trampoline reads the GOT entry and uses this as the destination address for the jump.
- If it is the first time of the function call, then the GOT entry points after the JMP instruction of step two. So the jump will just land after the jump instruction itself.
- The trampoline prepares for the resolver which shall resolve the binding ‘on demand’. That binder is a special entry in the PLT table at the beginning.
- The ‘binder’ gets called. He gets all the information (which library function to call and which GOT entry to update, so will perform the binding.
- Finally, the resolver calls the destination function in the library
The next time that library function gets called, the GOT entry contains the address of the shared library function: With one indirection the call ends up in the library:
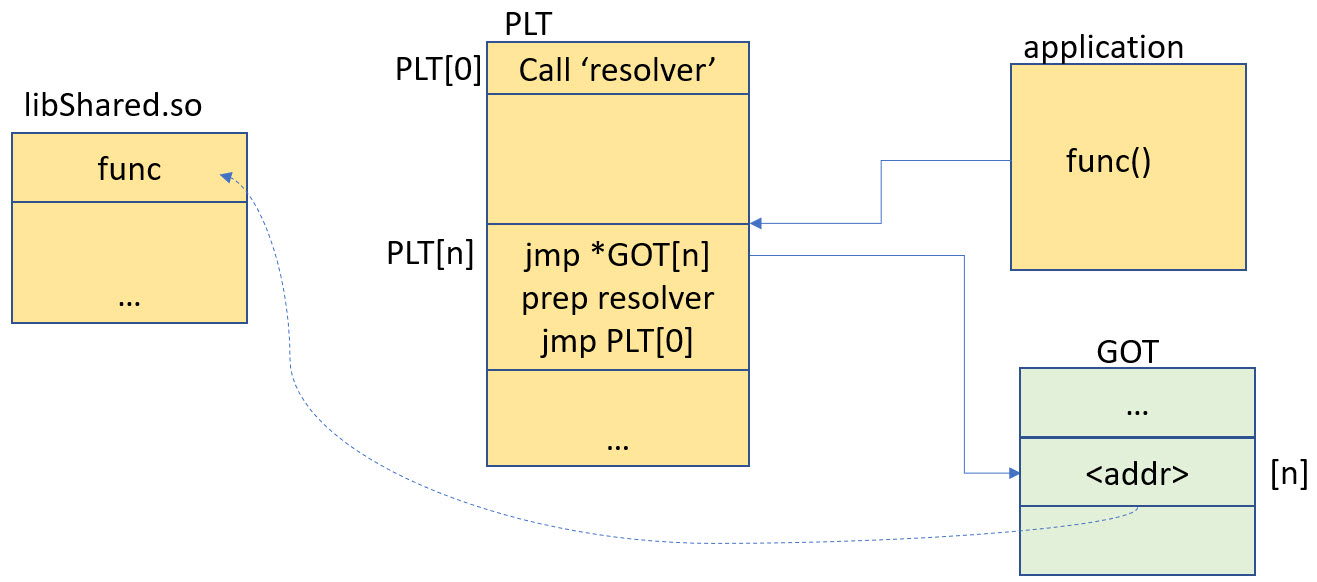
Let’s see how this works. In the application I call a function in the library:
i = MyLib_Calc(3);
Disassemble the ELF/Dwarf file with
arm-none-eabi-objdump -Dz --source LPC55S16_PositionIndependentCode.axf > app.dissIn the disassembly the call to the library function looks like this:
i = MyLib_Calc(3);
2d4: 2003 movs r0, #3
2d6: f001 fddb bl 1e90 <.plt+0x30> // call library function using PLT
2da: 4603 mov r3, r0
2dc: 4a0a ldr r2, [pc, #40] ; (308 <main+0x38>)
2de: 6013 str r3, [r2, #0]
It calls the stup in the PLT table:
bl 1e90 <.plt+0x30> // call library function with PLT entry
which is:
Disassembly of section .plt:
00001e60 <.plt>:
1e60: b500 push {lr}
1e62: f8df e008 ldr.w lr, [pc, #8] ; 1e6c <.plt+0xc>
1e66: 44fe add lr, pc
1e68: f85e ff08 ldr.w pc, [lr, #8]!
1e6c: 1fffe194 svcne 0x00ffe194
...
1e90: f24e 1c78 movw ip, #57720 ; 0xe178
1e94: f6c1 7cff movt ip, #8191 ; 0x1fff
1e98: 44fc add ip, pc
1e9a: f8dc f000 ldr.w pc, [ip]
1e9e: e7fc b.n 1e9a <.plt+0x3a>
first it does this first:
1e90: f24e 1c78 movw ip, #57720 ; 0xe178
1e94: f6c1 7cff movt ip, #8191 ; 0x1fff
1e98: 44fc add ip, pc
1e9a: f8dc f000 ldr.w pc, [ip]
This loads 0x1FFF’E178 into the ip (R12) register. This is the PC-relative offset to the GOT entry for the PLT. with ‘add ip,pc’ it calculates the GOT entry for the PLT:
0x1FFF'E178 (offset) + 0x1E98 (PC) + 4 = 0x2000'0014 The memory at 0x2000’0014 has the following:
0x2000'0014: 00001E61With this it jumps to the address 0x1E60 (the 1 bit is the thumb bit) which contains the following stub:
00001e60 <.plt>:
1e60: b500 push {lr}
1e62: f8df e008 ldr.w lr, [pc, #8] ; 1e6c <.plt+0xc>
1e66: 44fe add lr, pc
1e68: f85e ff08 ldr.w pc, [lr, #8]!
1e6c: 1fffe194 svcne 0x00ffe194
Here it loads the destination address from the PLT in a PC-relative way:
add lr,pc:
0x1FFF'E194 (offset) + 0x1E66 (PC) + 4 = 0x1FFF'FFFE
ldr.w pc,[lr,#8]
0x1FFF'FFFE (lr) + 0x8 = 0x2000'0006So it jumps to the destination address written in the GOT entry at 0x2000’0006.
One point is missing so far: how to bind the address in the GOT to the shared library function?
Program Header
The answer is not easy: because we are building a shared library, this means all the needed information to load the library is in the Program Header.
arm-none-eabi-readelf -l "libmystuff.so" > "libmystuff.so.readelf.dis"
gives
Elf file type is DYN (Shared object file)
Entry point 0x174
There are 3 program headers, starting at offset 52
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
LOAD 0x000000 0x00000000 0x00000000 0x00190 0x00190 R E 0x10000
LOAD 0x000190 0x00010190 0x00010190 0x00088 0x0008c RW 0x10000
DYNAMIC 0x000190 0x00010190 0x00010190 0x00078 0x00078 RW 0x4
Section to Segment mapping:
Segment Sections...
00 .hash .dynsym .dynstr .rel.dyn .text
01 .dynamic .got .bss
02 .dynamic
Such a program header is present for a normal ELF/Dwarf file too: this is what the debugger uses to load the program and program it to the target. The above list shows ‘segments’ and ‘sections’. Sections is what we deal with in the linker file with the SECTIONS block. The ELF/Dwarf file is organized in ‘segments’ which contain the ‘sections’.
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
LOAD 0x000000 0x00000000 0x00000000 0x00190 0x00190 R
Means “load the information with offset 0x0 in the file to the virtual (target destination) address, initialize it with the data at the physical address with the size 0x190 on the file which is the same size in memory, and this is for a R(ead-only) area”.
With
Segment Sections... 00 .hash .dynsym .dynstr .rel.dyn .text
we can see that the .text (code) is part of this segment (0). But now we have in our application not only the program headers from the main application, but as well the program header of the shared library. If we try to link our application with the shared library we will get a linker error:
error: PHDR segment not covered by LOAD segment
It means that we need to tell the linker what to do with the program headers.
In the most simplistic way we have to add a PHDRS entry to the linker file (see https://sourceware.org/binutils/docs/ld/PHDRS.html for details):
PHDRS
{
code PT_LOAD;
data PT_LOAD;
}
And then assign for each section to which program header they belong, for example:
/*------------------------------------------------------------- */
/* PLT section contains code for accessing the dynamically linked functions
* this measn functions from shared libraries in a position independent manner */
.plt : ALIGN(4)
{
*(.plt)
. = ALIGN(4);
} >PROGRAM_FLASH :code
/* The global offset table is the table for indirectly accessing the global variables
* The table contains addresses of the global variables. The text section contains
* a address of the GOT base and a offset in it to access the appropriate variables.
* This is done to access the variables in a position independent manner. */
.got : ALIGN(4)
{
_sgot = .;
*(.got)
} >SRAM AT> PROGRAM_FLASH :data
/* got.plt section contains entries which is used with the PLT to access the functions
* in a position independent manner. */
.got.plt : ALIGN(4)
{
_sgot_plt = .;
*(.got.plt)
_edata = .;
} >SRAM AT> PROGRAM_FLASH :data
/*------------------------------------------------------------- */
💡 Notice the ‘:code’ and ‘:data’ at the end of each section.
With this you should be able to link with the shared library.
Embedded Binding
Linking works, but it means that we still need to load the shared library. Instead writing a loader plus a method to bind the addresses at runtime, I’m using a simpler approach: the GOT entries bind with using a binding helper routine. The linker for the application will *not* include the shared library in the application: instead it is having the references and GOT entries to the shared library.
I’m using type for each binding like this:
/*! \brief
* The information needed to perform the binding.
* The offsets are the code offsets inside (Virtual address) from the beginning.
* The got_plt index is used to identify the got PLT index.
*/
typedef struct {
const char *name; /*!< name of function */
size_t offset; /*!< offset in loaded .code section */
int got_plt_idx; /*!< index in .got_plt table */
} binding_t;
An example binding table looks like this:
static const binding_t bindings[] =
{
{"MyLib_Calc", 0x0000, 4},
{"MyLib_Mul2", 0x0014, 5},
{"MyLib_Init", 0x0018, 3},
};
For the above table (kind of a ‘loader information), the offsets are based on where the code gets loaded into the memory. You can get the offsets e.g. with using readelf.
For the index into to the got/plt table: one way is to use ‘readelf -a’ on the binary too, which for example reveals the content/offsets too:
Relocation section '.rel.dyn' at offset 0x10364 contains 3 entries:
Offset Info Type Sym.Value Sym. Name
2000000c 00000116 R_ARM_JUMP_SLOT 00000000 MyLib_Init
20000010 00000216 R_ARM_JUMP_SLOT 00000000 MyLib_Calc
20000014 00000316 R_ARM_JUMP_SLOT 00000000 MyLib_Mul2
The binding is performed by the function below. ‘relocStart’ is the address where the shared library has been loaded:
extern unsigned int _sgot, _sgot_plt; /* symbols provided by the linker */
void BindLibrary(void *relocStart) {
for(int i=0; i<sizeof(bindings)/sizeof(bindings[0]); i++) {
((uint32_t*)&_sgot_plt)[bindings[i].got_plt_idx] = (uint32_t)(relocStart+bindings[i].offset);
}
}
Where to get the needed information? The ‘readelf’ of the shared library lists the program headers with the segments and relocation (VirtAddr,, PhysAddr) information:
Elf file type is DYN (Shared object file)
Entry point 0x174
There are 3 program headers, starting at offset 52
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
LOAD 0x000000 0x00000000 0x00000000 0x0018c 0x0018c R E 0x10000
LOAD 0x00018c 0x0001018c 0x0001018c 0x0008c 0x00090 RW 0x10000
DYNAMIC 0x00018c 0x0001018c 0x0001018c 0x00080 0x00080 RW 0x4
Section to Segment mapping:
Segment Sections...
00 .hash .dynsym .dynstr .rel.dyn .text
01 .dynamic .got .bss
02 .dynamic
Another way is to look at the disassembly which provides the position-indpendent-code plus the offsets:
Disassembly of section .text:
00000174 <MyLib_Calc>:
#include "myLib.h"
static int glob;
int MyLib_Calc(int x) {
glob++;
174: 4a02 ldr r2, [pc, #8] ; (180 <MyLib_Calc+0xc>)
176: 6813 ldr r3, [r2, #0]
178: 3301 adds r3, #1
17a: 6013 str r3, [r2, #0]
return x*2;
}
17c: 0040 lsls r0, r0, #1
17e: 4770 bx lr
180: 00010218 .word 0x00010218
00000184 <MyLib_Mul2>:
int MyLib_Mul2(int x) {
return x*2;
}
184: 0040 lsls r0, r0, #1
186: 4770 bx lr
00000188 <MyLib_Init>:
void MyLib_Init(void) {
}
188: 4770 bx lr
18a: bf00 nop
Notice the variable access in the above code to ‘glob’: this won’t work, so we have to look at the variables again for shared libraries.
Variables, again
We looked at how variables are accessed with -fPIC. Unfortunately adding -shared for shared libraries complicate things a bit more.
The concept with variables and shared libraries is that code is shared, but each process using the shared library has its own set of data. So in the case with an OS like Linux the loader is reserving the memory and your are done. In our case this is not needed. Still, the shared library needs to have a way to access data through the GOT.
The solution is to use the following compiler options:
-msingle-pic-base -mpic-register=r9 -mno-pic-data-is-text-relative -fPIC
This reserves the register R9 for PIC accessing and treats the register as read-only. Additionally it specifies that the displacement between text and data segments is fixed as discussed earlier. With this the access to the GOT is relative to R9:
Disassembly of section .text:
00000174 <MyLib_Calc>:
#include "myLib.h"
static int glob;
int MyLib_Calc(int x) {
glob++;
174: 4b03 ldr r3, [pc, #12] ; (184 <MyLib_Calc+0x10>)
176: f859 2003 ldr.w r2, [r9, r3]
17a: 6813 ldr r3, [r2, #0]
17c: 3301 adds r3, #1
17e: 6013 str r3, [r2, #0]
return x*2;
}
180: 0040 lsls r0, r0, #1
182: 4770 bx lr
184: 0000000c .word 0x0000000c
00000188 <MyLib_Mul2>:
int MyLib_Mul2(int x) {
return x*2;
}
188: 0040 lsls r0, r0, #1
18a: 4770 bx lr
0000018c <MyLib_Init>:
void MyLib_Init(void) {
}
18c: 4770 bx lr
18e: bf00 nop
The runtime environment is responsible to set up R9. In our case this is the startup code, where we do this like this:
__asm("LDR r9, =_sgot"); /* shared library data accesses go through R9 */
main();
With this we have both data and code position independent using a shared library :-).
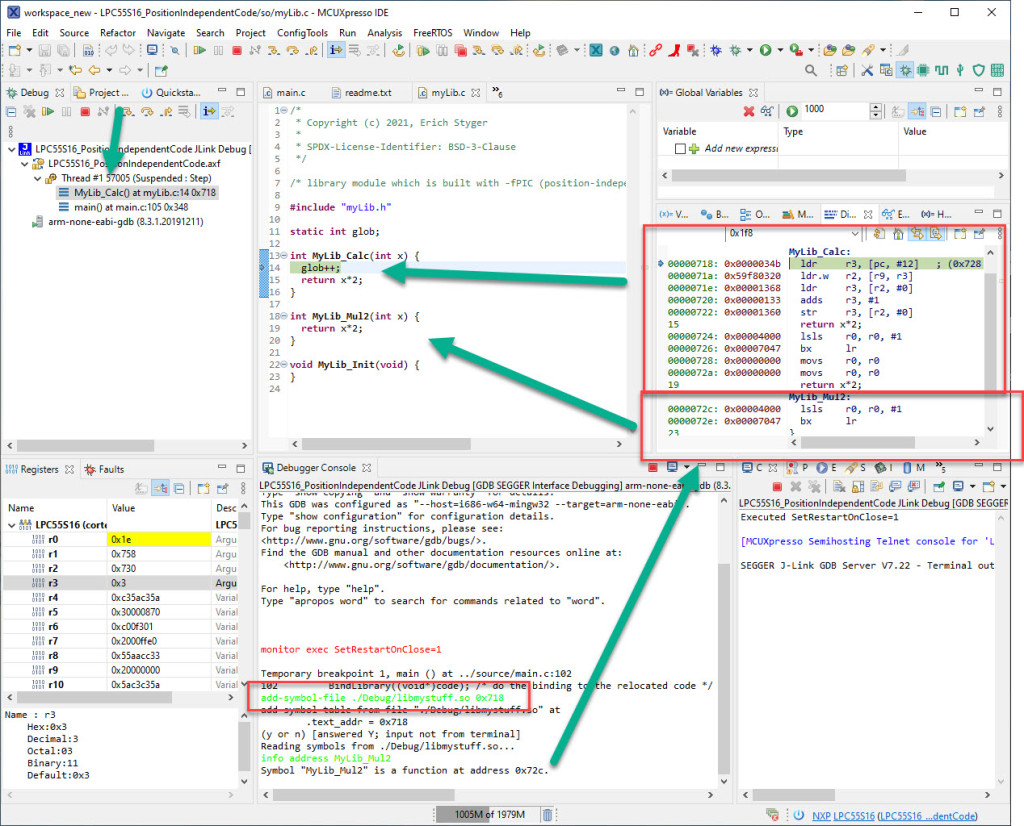
Debugging relocated or loaded code
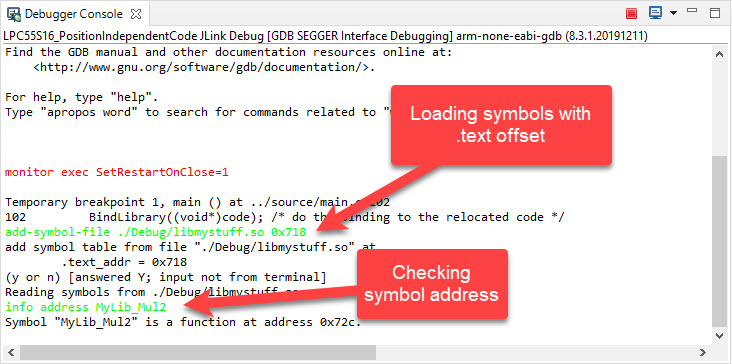
There remains one thing: how to debug code which has been moved around and/or is loaded dynamically? The solution is to tell gdb where the symbols are. For this we have to look again at the program header table of the shared library:
Elf file type is DYN (Shared object file) Entry point 0x174 There are 3 program headers, starting at offset 52 Program Headers: Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align LOAD 0x000000 0x00000000 0x00000000 0x00190 0x00190 R E 0x10000 LOAD 0x000190 0x00010190 0x00010190 0x00088 0x0008c RW 0x10000 DYNAMIC 0x000190 0x00010190 0x00010190 0x00078 0x00078 RW 0x4 Section to Segment mapping: Segment Sections... 00 .hash .dynsym .dynstr .rel.dyn .text 01 .dynamic .got .bss 02 .dynamic
The shared library is loading its code (.code) to the virtual (effective) address 0x0000’0000. Assuming I have loaded the .code of it at addres 0x718, then I can use the following gdb command in the debugger:
add-symbol-file ./Debug/libmystuff.so 0x718
The offset is the difference between the address in the header and the effective address in the memory. I can verify the resolution of a symbol with
info address MyLib_Mul2
which will tell me the address of it.
With this, I can debug moved/relocated/loaded code:
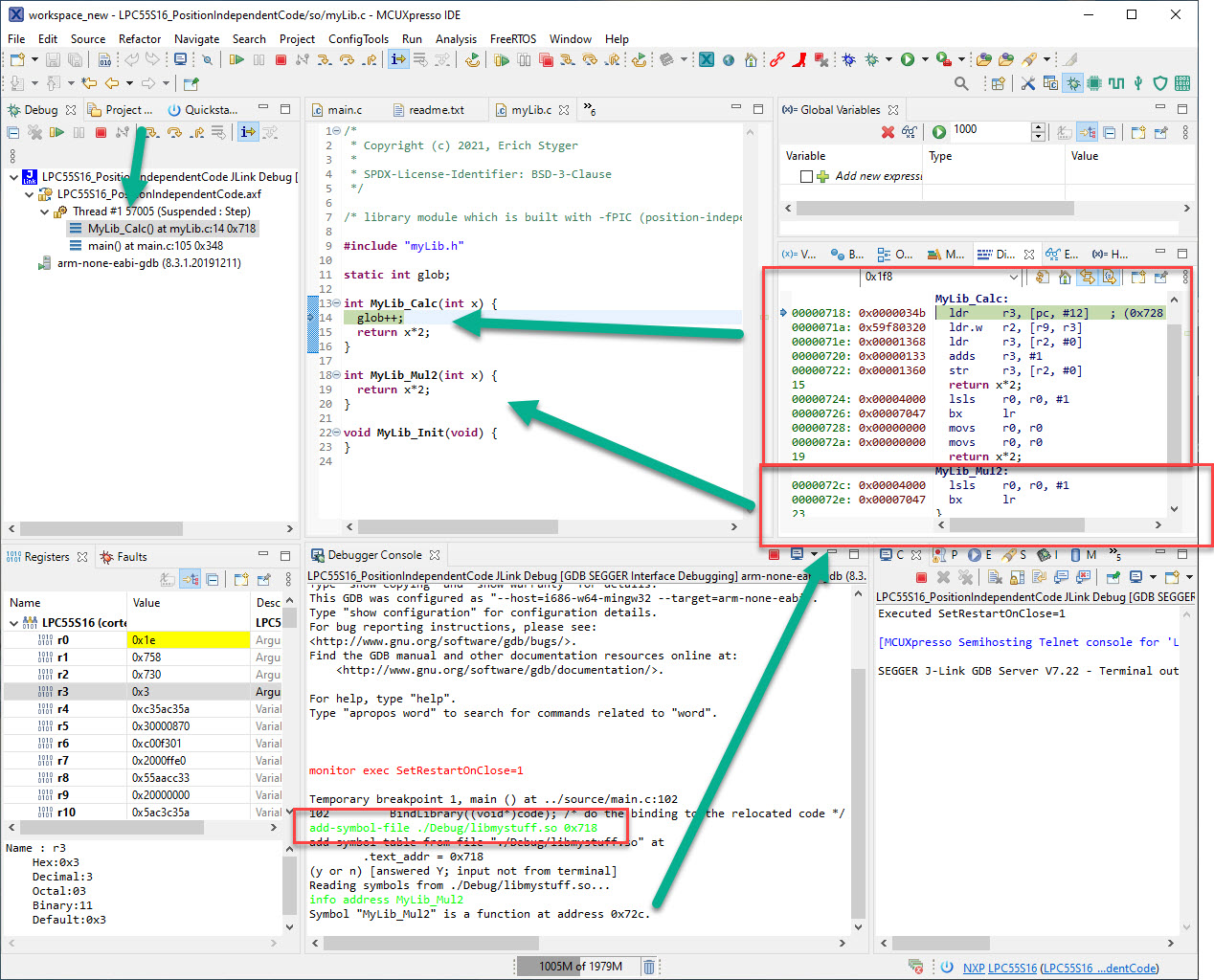
🙂
Summary
Uff! I hope you are still with me and reading. So if you ended up here (without cheating of course): congratulations, you made it into rabbit hole to the wonderland and back to the real world. You should now have all the knowledge to use position-independent code with shared libraries for your embedded project. Keep in mind that using PIC is not simple and with the extra indirections (GOT and PLT) there is a performance hit. But to have the ability to move code anywhere in the address space can be very useful.
As said at the beginning: this technology is not for everyone and every application. But it gives you hopefully yet another tool into your hands you can use.
💡 I know this is a complex topic, and I was thinking if I should make a short video with PIC in action. Post a comment if you are interested and I see what I can do.
Happy positioning 🙂
Links
- Project used in this article on GitHub: https://github.com/ErichStyger/mcuoneclipse/tree/master/Examples/MCUXpresso/LPC55S16-EVK/LPC55S16_PositionIndependentCode
- GCC code generation options: https://gcc.gnu.org/onlinedocs/gcc/Code-Gen-Options.html
- Linker PHDRS: https://sourceware.org/binutils/docs/ld/PHDRS.html
- The ‘Holy Grail’ of PIC: ttps://eli.thegreenplace.net/2011/11/03/position-independent-code-pic-in-shared-libraries
- Tutorial about using GOT: https://github.com/rgujju/STM32-projects/tree/master/got_plt
- GNU ARM Embedded compiler and -fno-plt: https://answers.launchpad.net/gcc-arm-embedded/+question/669758
- GNU ARM Embedded: PLT code with -mno-pic-data-is-text-relative: https://answers.launchpad.net/gcc-arm-embedded/+question/675869
- Modules with ThreadX: https://docs.microsoft.com/en-us/azure/rtos/threadx-modules/chapter1

Very good article about a useful topic.
This is something that I’ve wanted to explore especially in a FreeRTOS system where I add another executable which can access FreeRTOS (and system resources).
LikeLiked by 1 person
A full ‘executable’ or a FreeRTOS task? What I had in mind too was the ability to dynamically load tasks into the memory (FLASH or RAM) and execute it there. The ‘loader & binder’ I have used in this article is minimal, but could be extended to a more general ‘thread loader’ with FreeRTOS to accomplish what ‘higher-end’ RTOS or OS are doing.
LikeLike
“A full ‘executable’ or a FreeRTOS task?”
Actually both – Ideally a full executable that can take advantage of the FreeRTOS functions along with some base (ie IO – namely USB) tasks.
I’m really thinking of a more full-featured bootloader.
LikeLiked by 1 person
Yes, that’s certainly doable. For a loader you could read the ELF program header which should be pretty easy: it is a table with offsets into the file.
LikeLiked by 1 person
I *really* have to read up on the ELF file. ;^)
LikeLiked by 1 person
Vega has support for POSIX threads and relocatable executables:
– https://github.com/bmarcot/vega/blob/master/libc/pthread.c
– https://github.com/bmarcot/vega/blob/master/kernel/elf.c
Test case to load and execute PIE code:
– https://github.com/bmarcot/vega-test/blob/73bd7c4525379d34d62194774cb60b210f11c3c0/elf_1/main.c
Great article btw.
LikeLiked by 1 person
Excellent write up!
LikeLiked by 1 person
Thank you.
LikeLike
This level of functionality would be a useful addition to the RT Series crossover processers since they’re suited to applications that could otherwise be done with more complex and expensive devices. I suppose it would be possible to download a shared library containing LVGL functions and make a system equipped with a touchscreen display different graphics and GUI objects. On the subject of shared libraries , can the compiler generate a checksum of it? There is great potential for corruption or security issues with this added flexibility.
LikeLiked by 1 person
Hi Chad,
yes, the RT series would benefit from that too. You could build a machine with different options (e.g. with or without touch screen) and then it would load the needed shared library or something different. The compiler would not be the place to generate the checksum, but the linker or what I’m using is the SRecord tool (see https://mcuoneclipse.com/2015/04/26/crc-checksum-generation-with-srecord-tools-for-gnu-and-eclipse/) as with this I have the greatest flexibility.
LikeLike
Interesting article. There is already a dynamic loader for cortex M in git. The author didnt advanced it further but its a start for those that need to resolve linkage at run time.
https://github.com/bogdanm/udynlink
LikeLiked by 1 person
Hi Hugo,
thanks for that link, I have not seen that loader. It looks interesting, indeed a good starting point.
LikeLike
Very cool article!
A year ago I was looking more in-depth into the topic, I and a few others got stuck because we simply did not have this excellent in-depth knowledge of the entire topic. Best resource was an old SO question (https://stackoverflow.com/questions/15386970/position-independent-executable-pie-for-armcortex-m3). Glad to see this project.
LikeLiked by 1 person
Hi Avamander,
thank you! Yes, it has been a difficult area for me too, and it took me much longer than expected to get it working. And I did not find much on that topic neither on the internet, so I thought I need to write up what I have found and how I was able to get it working, at least as a proof of concept.
Erich
LikeLike
It is a very good article to cover such a difficult topic. I do hope that a short video is coming soon. Thank you very much.
LikeLiked by 1 person
Thank you, still need to find some time for it, as creating videos is very time consuming.
LikeLike
yes video is very important as understanding this theoretically is fine but practically it is a must.
LikeLiked by 1 person
as for using practically: simply try and run my example project with the debugger.
LikeLike
Thank you for this wonderful article. It helps me to understand position independent code better. I have one question, Can C++ code can be made position independent?
LikeLiked by 1 person
Hi Vishnu,
yes, the concept is the same for any programming language, including C++.
LikeLike
Would you like to make the similar description for -fPIE?
My problem is, I’m usind a bootloader, which is able to select the memory range with different firmware images. But with -fPIC no one of the Images starts.
Without the flag the image starts only if it was compiled for a specific location. For example image compiled to be placed to 0x1000. It starts in case it placed to 0x1000 but not if it is loaded to 0xC000. (not a problem if IAR compiler with -ropi (the same as -fPIC/PIE) is used)…
LikeLiked by 1 person
I cannot commit to this. Alone the first article took me about a year from the beginning to the end, and currently I have no need for -FPIE.
LikeLike
Hi ,
I have compiled your example PIC(LPC55S16_PositionIndependentCode) code , and from map file
i can see that size of .got is zero
0x4 LONG 0x0 SIZEOF (.got).
Is any thing i m missing .
And if try to run the code i m getting hardfault.
LikeLiked by 1 person
Yes, that could be ok. I’m away from the hardware/board right now, so I cannot re-check. But it should not hard-fault.
LikeLike
In between , i have compiled this code for cortex m0+ , and got the error thumb-1 mode PLT generation not currently supported ,Is there any workaround for this error .
LikeLiked by 1 person
I had had the same observation on M0. I did not find any workaround for it. And somehow I don’t understand why this is not supported on M0, as I don’t see a technical reason for it. Or do you know?
LikeLike
I guess the required thumb instruction for this operation is not available in ARMv6 Arch.
However, your article is in a well-structured manner, which breaks complex things into a bit easier.
Keep posting!
LikeLiked by 1 person
I’m wondering what would be missing for PIC in the instruction set? And thanks for your feedback! My time is very limited, so I try to give back to the community as much as possible.
LikeLike
Hello Erich,
First i want to thank you for your research and sharing the knowledge…
Can you explain how the share object (.so file) be flashed in target?
LikeLiked by 1 person
The easiest way is to load it as a .bin file from the target, so you won’t have to parse the .so itself: transmit/store the .so as .bin to the target system, with the extra binding information if needed, then program the file into the flash memory.
LikeLike
I am using STM32Fxxx, i need to flash .so file in stm32. Could you please tell me how to convert .so file into .bin file?
LikeLike
How to transfer .so file and store it as bin file into the target ?
LikeLiked by 1 person
You do not need to ‘transfer’ the .so file. Simple convert it to a .s19, .hex or .bin. See for example https://mcuoneclipse.com/2017/03/29/mcuxpresso-ide-s-record-intel-hex-and-binary-files/ how you can easily do this with any eclipse based IDE. Or simply use a make file or console:
arm-none-eabi-objcopy -v -O binary “libmylib.so” “libmylib.bin”
LikeLike
Thank you so much…. And many thanks for your quick response to resolve my doubts…
LikeLiked by 1 person
you are welcome!
LikeLike
Hello Erich,
I am hitting hard fault error when my library function first instrcution got executed.
Disassembly of section .text:
000000f8 :
f8: b480 push {r7}
fa: b083 sub sp, #12
fc: af00 add r7, sp, #0
fe: 6078 str r0, [r7, #4]
100: 687b ldr r3, [r7, #4]
102: 2264 movs r2, #100 ; 0x64
104: fb02 f303 mul.w r3, r2, r3
108: 4618 mov r0, r3
10a: 370c adds r7, #12
10c: 46bd mov sp, r7
10e: bc80 pop {r7}
110: 4770 bx lr
I did binding by updating got.plt table with my library function address, everything is working fine starting from plt entry but when it enters library function 1st instruction execution “push {r7}” it gets hard fault error. Kindly check this
LikeLike
what is your stack pointer (MSP or PSP) at the time of the push? I suspect your stack pointer points to a memory area not in RAM?
LikeLike
My end of stack is 0x2008-0000, MSP points to “0x2007-ffec” when the instruction “push {r7}” starts for execution.
LikeLiked by 1 person
Is that your end of RAM? Can you try to move your stack pointer away from it, just for checking? I ask because I have seen debug probes reading memory for caching and this might trigger hard faults if the memory is not accessible.
LikeLike
Can you confirm the way that i am updating(binding) the got.plt at the initialization is correct
/// initiation code before while loop to bind lib function
uint32_t *ram_ptr_a = (uint32_t*)0x20000006;
*ram_ptr_a = (uint32_t)0x08100000;
0x20000006 >> is the address of got.plt for the library function
0x08100000 >> is the start address of library function.
Address 0x20000006 is calculated by referring the below following steps as you mentioned in tutorial
add lr,pc:
0x1FFF’E194 (offset) + 0x1E66 (PC) + 4 = 0x1FFF’FFFE
ldr.w pc,[lr,#8]
0x1FFF’FFFE (lr) + 0x8 = 0x2000’0006
So it jumps to the destination address written in the GOT entry at 0x2000’0006.
Note: i didn’t use your same address 0x2000’0006, i got the same address for my program as well.
LikeLiked by 1 person
I suggest you have a look at my code and application. Keep in mind that for the actual call it jumps first to the resolver routine and then to the actual library code.
LikeLike
Hello Erich,
Could you please explain why the instruction opcodes are loaded in to the plt table address (got.plt )
static const int16_t code[] = {
0x4b03,
0xf859, 0x2003,
0x6813,
0x3301,
0x6013,
.
.
}
it assign library function opcodes (instruction – 0x4b03) to got.plt table.
((uint32_t*)&_sgot_plt)[bindings[i].got_plt_idx] = (uint32_t)(relocStart+bindings[i].offset);
But I expect library function start address (0x174 + offset of flash address) to be assigned with got.plt instead of assigning opcodes to it.
int MyLib_Calc(int x) {
glob++;
174: 4b03 ldr r3, [pc, #12] ; (184 )
176: f859 2003 ldr.w r2, [r9, r3]
17a: 6813 ldr r3, [r2, #0]
17c: 3301 adds r3, #1
17e: 6013 str r3, [r2, #0]
return x*2;
}
I did binding by: ((uint32_t*)&_sgot_plt)[bindings[i].got_plt_idx] = 0x81000174 >> ( 0x81000000 + 0x174 = 0x81000174)
Please check this….
LikeLike
Hello Erich, My issue is resolved.
When we load branch address to PC, we should increment the address by 1 then load it to PC.
/// initiation code before while loop to bind lib function
uint32_t *ram_ptr_a = (uint32_t*)0x20000006;
*ram_ptr_a = (uint32_t)(0x08100000 + 1);
Here I incremented address by 1, It resolves my issue.
LikeLike
If you call things with a function pointer, then you have to have the LSB set (it is called the ‘ARM Thumb Bit’), otherwise you are going to call a non-Thumb code (which is not supported in the Corex-Mx)
LikeLike
Hello Erich,
When I compiled your code, the size of got section is 0 but your myLib.c is accessing global data variable “glob”.
static int glob;
int MyLib_Calc(int x) {
glob++;
return x*2;
}
.got 0x20000000 0x0 load address 0x0000087c
0x20000000 _sgot = .
*(SORT_BY_ALIGNMENT(.got))
.got 0x20000000 0x0 ./startup/startup_lpc55s16.o
Without got section how can we handle the global variable available inside the library file?
Please suggest…
LikeLike
You have to fill the got table for the variables addresses too.
LikeLike
Since the variable is in .so file, the got table of .so file is not added in LPC55S16_PositionIndependentCode.axf , So how can we do update got table of variables available in library file?
LikeLike
This is what your loader has to provide (load from the .so file, or data added to your .bin file or whatever).
LikeLike
Please explain what loader means, Is it a specific software we need to do write/develop Or it is a compiler option ?
LikeLike
The loader is the program or code which loads a module or a piece of code. A ‘bootloader’ (see https://mcuoneclipse.com/tag/bootloader/) one implementation of it, which loads a full application. If you start a program on the host (Windows, Linux, …) then it is a loader which loads the binary and starts the execution. In the embedded space or for a shared module/so/dll file: the loader reads the information needed to load and execute the binary or load that piece of code.
LikeLike
Hello Erich,
very good article! Also much complex..
My interest is to launch an application code from small boot-loader after reception by serial channel
of s19 file with image of application.. then is not important to maintain the boot-loader operative (as calling a custom library) but this can dead and release all RAM for the application, positioned high in flash..
What is an easy mode to compile my application code so that run? Only -fPIC flag?
LikeLiked by 1 person
Hi Antonio,
If you just have a RAM/ROM area reserved for your application, then you don’t need PIC and can keep the application with fixed addresses. So no -fPIC needed for your case. Just in case if you want to use a ROM lib in addition to that, see https://mcuoneclipse.com/tag/rom-library/
LikeLike
Hi Erich, and then.. why if I launch a sample application (cortex M4, MCUXpresso..) builded with -fPIC not flagged the application RUN correctly, but if I flag -fPIC, without change any location address for RAM and FLASH, the application crash?
LikeLiked by 1 person
Hi Antonio,
I’m sorry, I don’t really understand what you mean? -fPIC really creates different code, and depending on what you do with you code, you might not have set up the system properly?
LikeLike
Pingback: ¿Puedo vincular estáticamente un ejecutable vinculado dinámicamente? - executable en Español
Very nice article, thanks!
LikeLike
Thank you, you are welcome!
LikeLike
Hello Reich!
I’ve realized some similar features, and I then came across your article, it’s splendid!
About the debugging, I still have one more problem, the command for gdb is targetted at the text section, but for bss and data section, due to relocation of global varaibles, the debugger could not get the correct value of the data, and I need to use memory dump to manually analyze. Propably we need to specify two add-symbol command, one for text and one for bss and data part.
LikeLike
Hi Ray,
the add-symbol command is both for code and data.
LikeLike
Sorry for the bad explanation. In my case, the offsets for code and data are different, using ‘add-symbol-file xxx.elf -o 0x1000’ does not work, so I need to specify like this ‘add-symbol-file xxx.elf -o 0x1000 -s .text 0x08020000’ so both code and data can re located to the correct place by the Debugger
LikeLike
Hi Ray,
thanks for the extra information. This makes sense now.
LikeLike